


The Project
Goals / Objectives
GeoGen3DHuman aims for developing deep learning techniques for high-dimensional and non euclidean data such as surface meshes. Future innovation in this domain will be applied to investigate how the generated data can be used to train a new generation of automatic human analysis systems such as face and facial expression recognition, hand and body gesture recognition to name a few.
Generative models have demonstrated their effectiveness in several image domains, with applications that go from data augmentation for better training of convolutional neural networks to the generation of face images of astonishing realism that are mostly indistinguishable from real one even for a human observer. Less work has been done on generative models working in non-Euclidean domains. Some examples exist for body and face generation, with traditional methods as 3D morphable model like solutions that are still competitive with neural network based methods. Moreover, models that also account for the temporal dimension, being capable of generating non-Euclidean instances along the time while preserving smoothness, coherence and realism are still at the beginning.
Our idea here, it to develop generative models in non-Euclidean domains that can operate along the time. In doing so, one important aspect is represented by the entanglement between the temporal and spatial domain. Our goal is to investigate solutions that disentangle the temporal and spatial domain so as to obtain a better control of the two components and also make the results more interpretable.
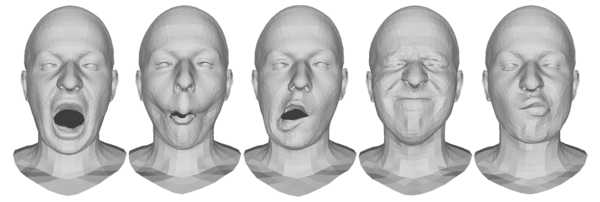
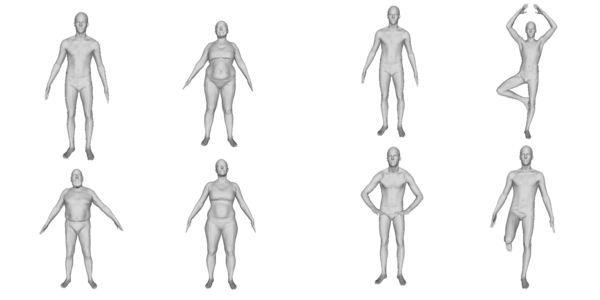
We target applications that use 3D models of the face and of the human body. For face, there is an increasing demand for solutions that, on the one hand use the 3D face for identity and expression recognition, and for medical analysis (e.g., pain detection, cosmetic surgery, stroke recovery, Alzheimer's disease monitoring), on the other allow generating realistic animated faces as needed in virtual reality, film industry, human-avatar interaction, talking head animation and several others.
Research
3D computer vision is a field of computer vision that focuses on analyzing and understanding the world in three dimensions. It involves capturing and processing 3D data using a range of sensors and imaging devices, such as cameras, depth sensors, and LIDAR.
The acquired 3D data can be understood in terms of surfaces or curves in euclidean space. Processing such complex geometries require advanced mathematical techniques from shape analysis.
Simulating humans is a specific task with wide variety of applications